Optimizing Query Compilation in Hive 4 on MR3
Oct 9, 2024
Read in 6 minutes
Introduction
In our previous article, we evaluated the performance of Hive 4 on MR3 1.11 and Trino 453 on the 10TB TPC-DS benchmark. The results can be summarized as follows:
- In terms of the total running time, Hive 4 on MR3 runs slightly faster than Trino – Hive 4 on MR3 5744 seconds vs Trino 5798 seconds.
- In terms of the geometric mean of running times, Trino responds about 15 percent faster than Hive 4 on MR3 – Trino 17.99 seconds vs Hive 4 on MR3 21.02 seconds.
While there is no clear winner (because Trino returns wrong answers on query 23 and query 72), we observe that Trino runs significantly faster on some queries in the TPC-DS benchmark, as shown in the following table (in seconds):
| Query | Hive 4 on MR3 | Trino |
|---|---|---|
| Query 58 | 72.943 | 5.584 |
| Query 67 | 842.356 | 325.701 |
| Query 75 | 224.221 | 105.102 |
We set out to investigate the source of the poor performance of Hive 4 on MR3 on such queries. After analyzing query plans generated by Trino and Hive 4 on MR3, we identified three categories of queries for which Trino produced more efficient query plans. For each category, we implemented a patch for generating query plans similarly to Trino and/or fixing the bug hindering the performance. These patches are HIVE-28488, HIVE-28489, and HIVE-28490.
Before presenting experimental results of applying the three patches, we explain each patch in more detail (which is rather technical and can be skipped).
HIVE-28488
When a query applies union operators to 3 or more tables,
Hive 4 appends a group-by operator to each union operator,
resulting in a query plan that resembles a binary tree.
This patch merges adjacent union operators into a single union operator.
In addition, it fixes a bug in Hive 4 that inserts a redundant group-by operator.
As a result,
this patch reduces the number of shuffle stages in a query with multiple union operators.
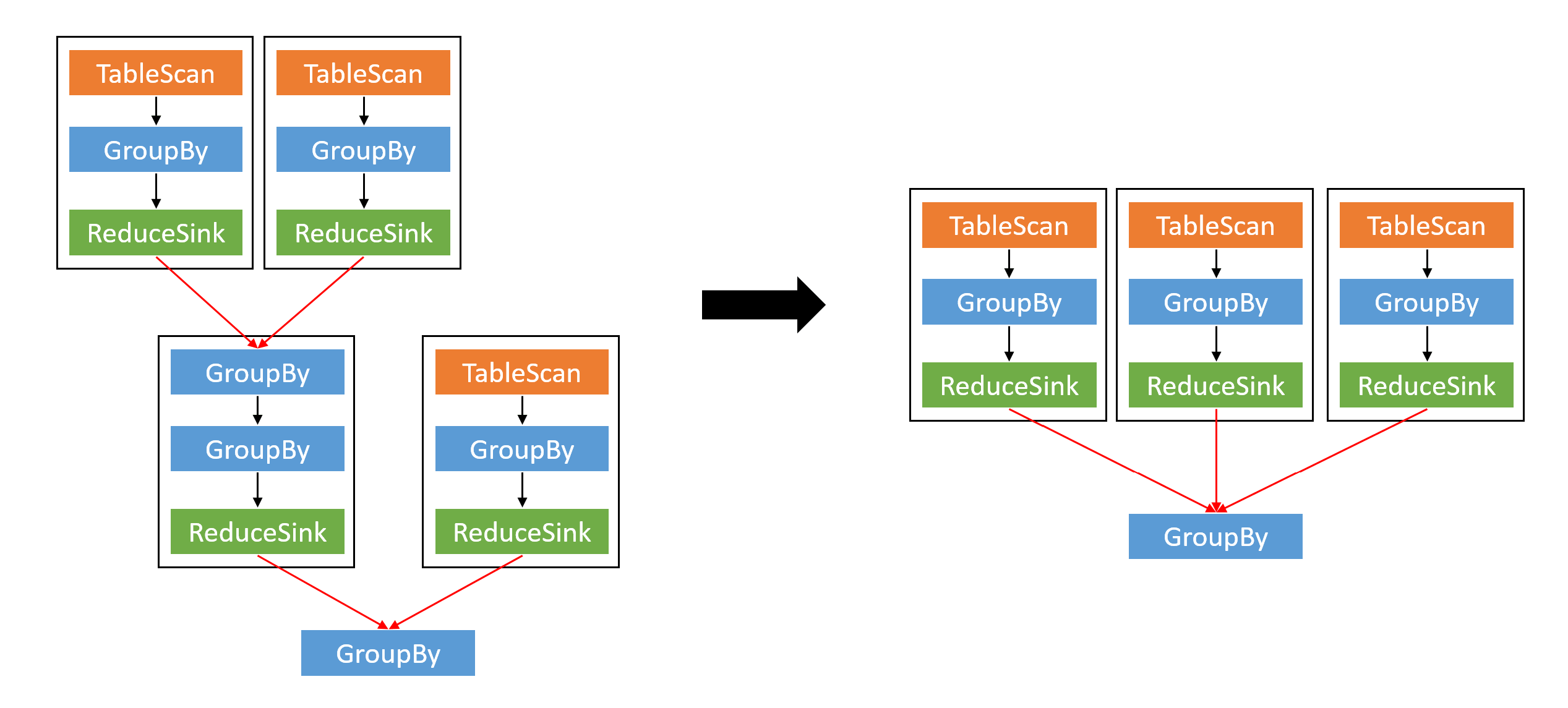 Queries affected by HIVE-28488: query 49 and query 75.
Queries affected by HIVE-28488: query 49 and query 75.
HIVE-28489
A group-by operator with grouping sets often emits an excessive number of records,
significantly delaying query execution.
On the 10TB TPC-DS benchmark, for example,
a single group-by operator in query 67 emits about 40 billion (41,380,289,606) records
and the corresponding shuffle stage takes up a large portion of the running time.
This patch aims to reduce the number of records emitted by the group-by operator
by introducing a preliminary reduce-sink operator that only performs partitioning
on the column with the highest number of distinct values.
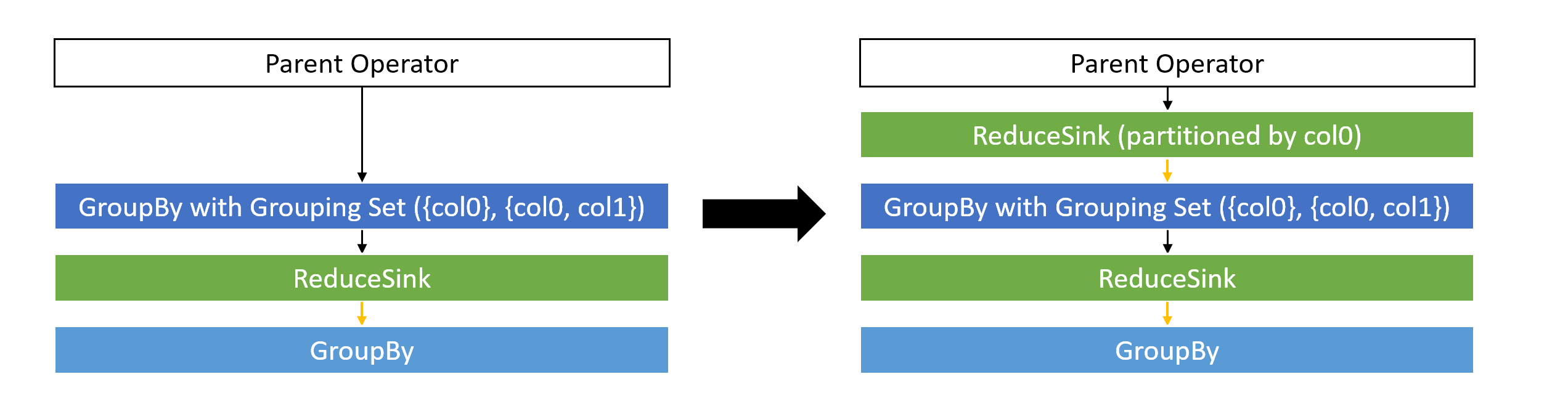 Since inserting an additional shuffle stage can increase the running time,
this patch selectively transforms the query plan.
For example, it has no effect
if the input data of the group-by operator is already partitioned.
Since inserting an additional shuffle stage can increase the running time,
this patch selectively transforms the query plan.
For example, it has no effect
if the input data of the group-by operator is already partitioned.
Queries affected by HIVE-28489: query 18, query 22, and query 67.
HIVE-28490
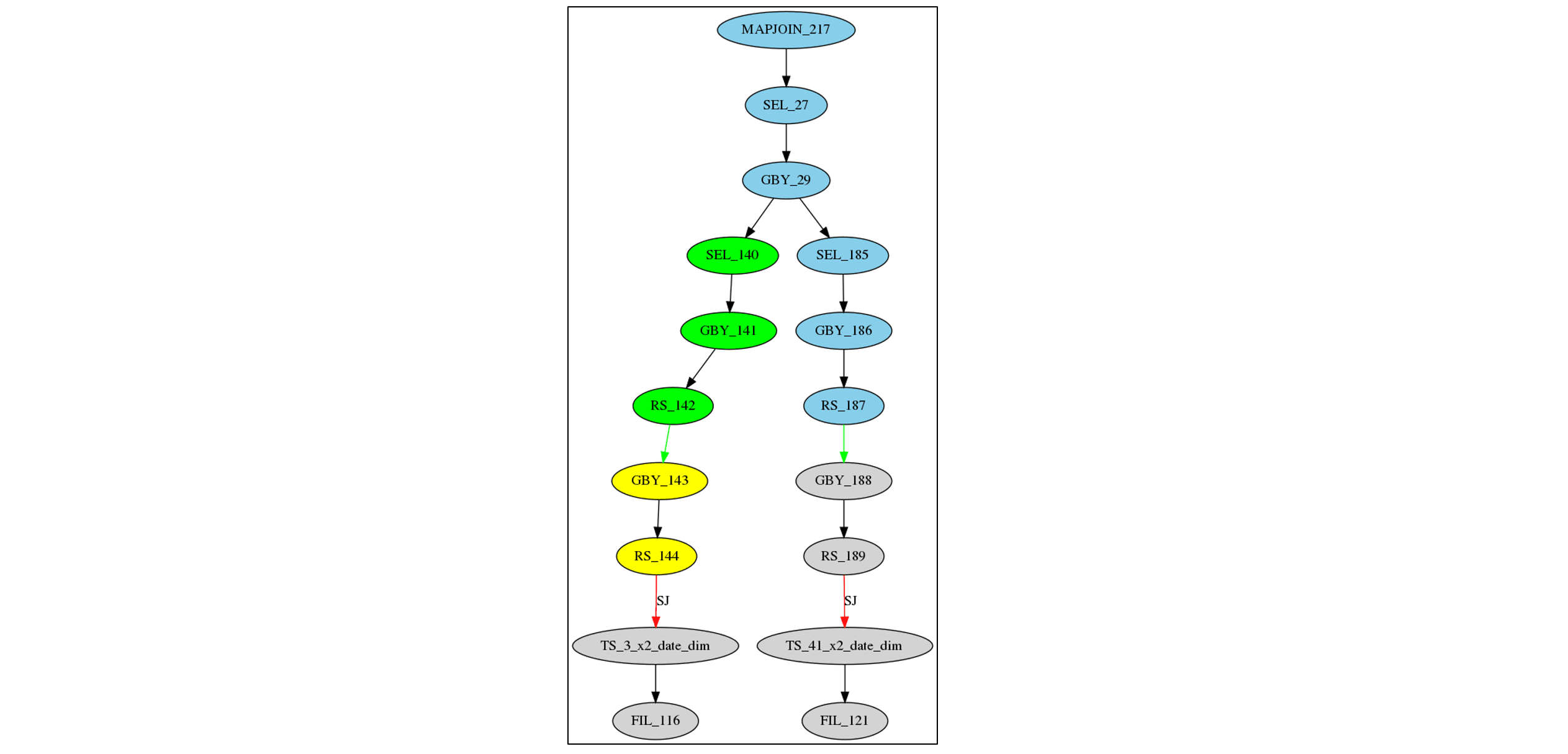
We identified a bug in Hive 4 that
the method findAscendantWorkOperators() of SharedWorkOptimizer
occasionally miscalculates the set of ascendant operators of a given operator.
For example,
in the following query plan from query 58 of the TPC-DS benchmark,
findAscendantWorkOperators()
incorrectly includes SEL_140, GBY_141, and RS_142
as ascendant operators of RS_189.
 As a result, Hive 4 generates a much less efficient query plan than Trino.
This patch fixes the bug to ensure that findAscendantWorkOperators()
returns a correct set of ascendant operators.
As a result, Hive 4 generates a much less efficient query plan than Trino.
This patch fixes the bug to ensure that findAscendantWorkOperators()
returns a correct set of ascendant operators.
Queries affected by HIVE-28490: query 58 and query 83.
Experiment Setup
To evaluate the performance improvement after applying the three patches, we repeat the experiment from our previous article using the following systems.
- Hive 4 on MR3 (basic) – Hive 4.0.1 on MR3 1.12 without HIVE-28488/28489/28490.
- Hive 4 on MR3 (optimized) – Hive 4.0.1 on MR3 1.12 with HIVE-28488/28489/28490.
- Trino 453
We maintain the same configuration and cluster setup from the previous experiment, with the scale factor of the TPC-DS benchmark remaining at 10TB.
Test
We sequentially submit 99 queries from the TPC-DS benchmark. We report the total running time, the geometric mean of running times, and the running time of each individual query.
Raw data of the experiment results
For the reader's perusal, we attach the table containing the raw data of the experiment results. Here is a link to [Google Docs].
Analysis
#1. Queries affected by the patches
The following table shows 7 queries affected by the three patches and their running times (in seconds). No other queries are affected by the patches during query planning.
| Patch | Query | Hive 4 on MR3 (basic) | Hive 4 on MR3 (optimized) | Trino |
|---|---|---|---|---|
| HIVE-28488 | query 49 | 24.402 | 24.197 | 12.123 |
| query 75 | 240.678 | 202.841 | 103.489 | |
| HIVE-28489 | query 18 | 37.135 | 33.289 | 13.256 |
| query 22 | 57.971 | 15.981 | 7.584 | |
| query 67 | 843.129 | 432.035 | 306.151 | |
| HIVE-28490 | query 58 | 75.691 | 8.7 | 5.873 |
| query 83 | 20.58 | 14.328 | 6.42 |
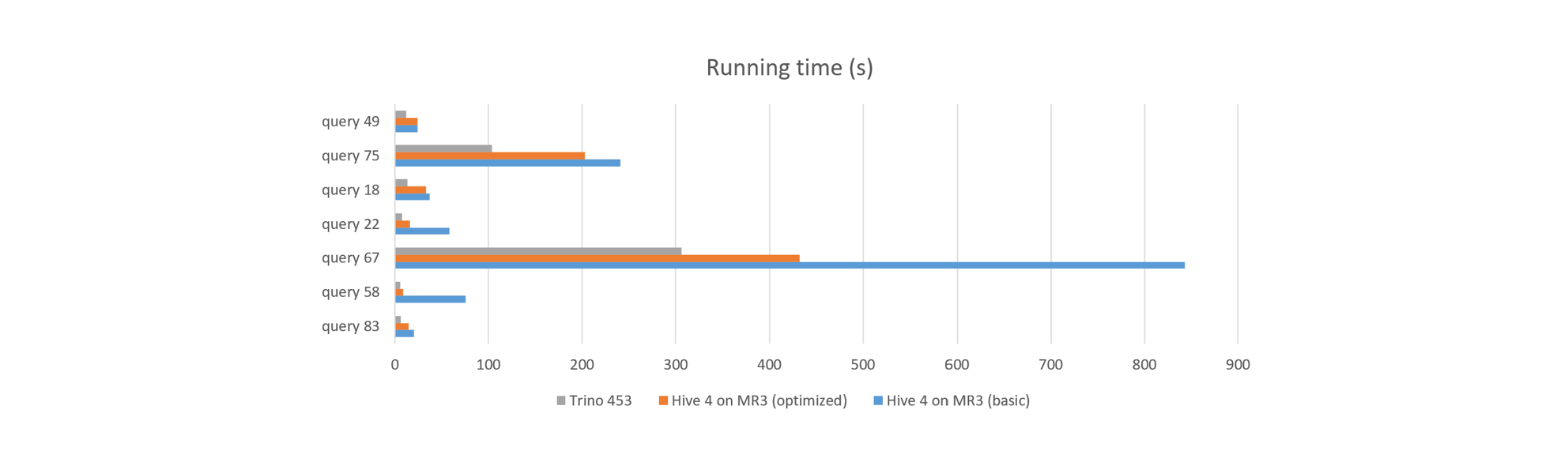
With the patches applied to Hive 4 on MR3, we observe moderate to significant improvements in running times. In particular, the reduction in the running time of query 67 (from 866.436 seconds to 432.035 seconds) allows Hive 4 on MR3 to outperform Trino on the entire TPC-DS benchmark, as shown below.
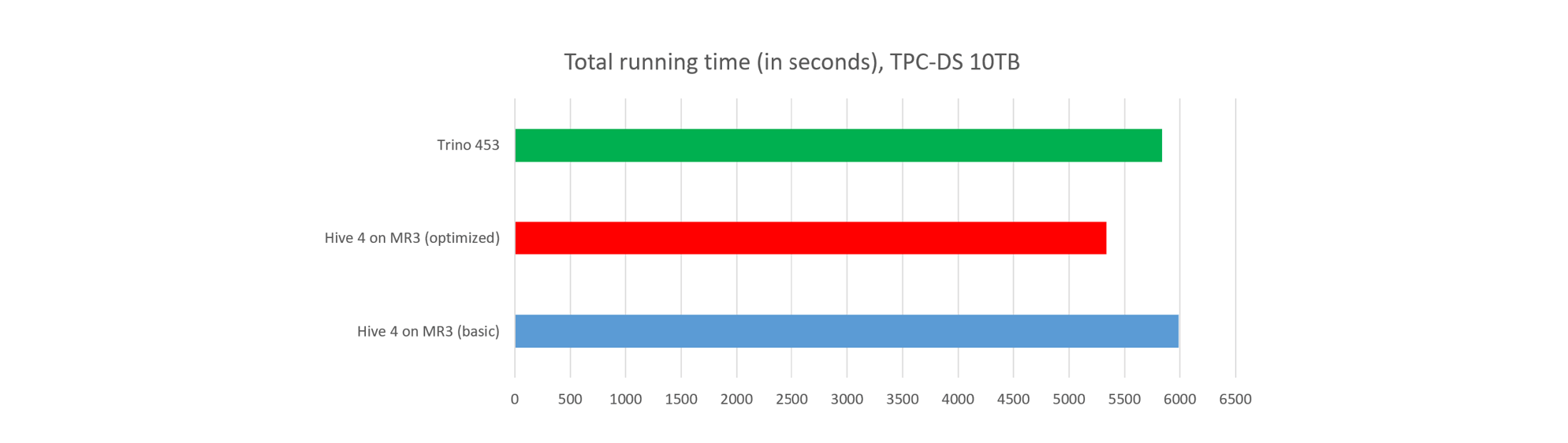
#2. Total running time
The three patches reduce the total running time of Hive 4 on MR3 by about 10 percent. Note that in terms of the total running time, Hive 4 on MR3 (optimized) now runs clearly faster than Trino.
- Hive 4 on MR3 (basic) finishes all the queries in 6092 seconds.
- Hive 4 on MR3 (optimized) finishes all the queries in 5338 seconds.
- Trino finishes all the queries in 5839 seconds.
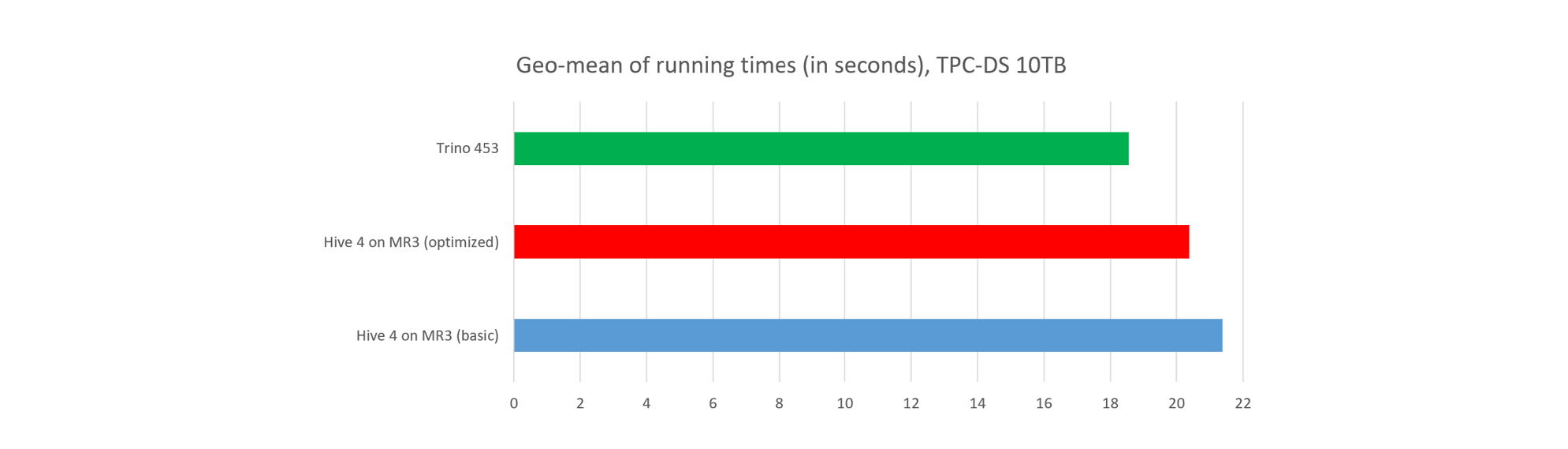
#3. Response time
In terms of the geometric mean of running times, Trino still responds about 10 percent faster than Hive 4 on MR3.
- On average, Hive 4 on MR3 (basic) finishes each query in 22.02 seconds.
- On average, Hive 4 on MR3 (optimized) finishes each query in 20.38 seconds.
- On average, Trino finishes each query in 18.55 seconds.
Conclusion
With the recent release of Hive 4.0.1 and the announcement of the end of support for all the previous versions including Hive 3.1, Apache Hive is reshaping itself by concentrating all development efforts on Hive 4. Correctness bugs are quickly fixed upon discovery, and performance improvements are consistently implemented at all layers. Ease of use, however, is still not a hallmark feature of Apache Hive. For example, installing Apache Hive requires a specific version of Hadoop and does not work on Kubernetes. Furthermore deploying it in LLAP mode is far from trivial, and performance tuning is often a long and painstaking journey (which unfortunately turns away many users). Because of its dependence on Hadoop and the execution engine Tez, it remains unclear if these problems can be resolved in the foreseeable future.
Hive on MR3 addresses these challenges of Apache Hive, providing ease of use comparable to popular solutions such as Trino and Spark. For example, Hive on MR3 can be run in standalone mode without requiring a resource manager like Hadoop or Kubernetes. In addition, it offers a performance level that surpasses Hive with LLAP and continues to evolve with new features, such as support for remote shuffle service (Apache Celeborn).
If you are interested in Hive on MR3, join MR3 Slack or see Quick Start Guide.